单元测试4 - 机器学习中级 (2022-08-26)
1. 根据图中标识的参数回答1-6特征层的通道和高度两个维度的值
题目
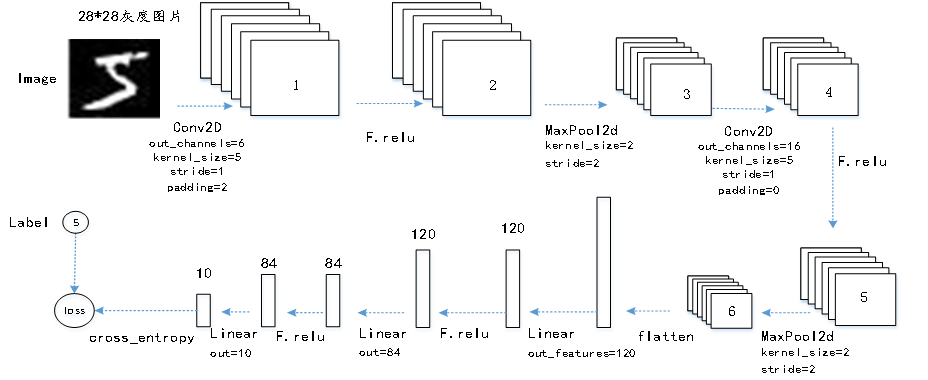
LeNet网络是经典的卷积网络, 在手写数据识别中大获成功, 也是深度演习中的经典案例。它通过卷积、非线性变换、全连接及概率映射等计算构建概率模型。请根据图中标识的参数回答1-6特征层的通道和高度两个维度的值. (注意, 本模型采用的维度顺序是NCHW,线性计算均有偏移量参数)。
特征层1的通道数为[填空1], 高度为[填空2];
特征层2的通道数为[填空3], 高度为[填空4];
特征层3的通道数为[填空5], 高度为[填空6];
特征层4的通道数为[填空7], 高度为[填空8]
输出图像到特征层1之间共有模型参数[填空9]个, 从层1到层2共有模型参数[填空10]个.
2. 利用pytorch框架的nn.Sequential函数, 构建上图计算图
题目
2.利用pytorch框架的nn.Sequential函数, 构建上图计算图. 请补充代码.
import torch.nn as nn
def LeNet():
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.ReLu(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5, padding=O),
nn.ReLu(),
nn.MaxPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(120, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLu(),
nn.Linear(84, 10)
)
return net
答案
3. 通过继承pytorch的nn.Modle对象来实现同样的效果
题目
前一题的模型也可通过继承pytorch的nn.Modle对象来实现同样的效果.
答案
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 400)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
4. 完成的pytorch模型的训练
题目
利用前面定义的计算图, 完成的pytorch模型的训练.
答案
import numpy as np
import random
import struct
import torch
import torch.functional as F
import torch.nn as nn
from torch import optim
def train(loader, num_epoch=2, net_cls='LeNet'):
model = MnistNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
for epoch in range(num_epoch):
running_loss = 0.0
for i, data in enumerate(loader()):
inputs, labels = zip(*data)
inputs = np.array(inputs).astype('float32')
labels = np.array(labels).astype('int64')
inputs = torch.from_numpy(inputs).unsqueeze(1)
labels = torch.from_numpy(labels)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 0:
print('[%d, %5d] loss: %.3f' % epoch + 1, i + 1, running_loss / 100)
running_loss = 0.0
return model
PATH = './mnist_pytorch.pth'
train_loader = dataReader('train.images', 'train.labels', 16, True)
model = train(train_loader)
torch.save(model.state_dict(), PATH)
5. pytorch模型参数的加载与测试
题目
pytorch模型参数的加载与测试.
答案
def test(PATH, loader):
model = MnistNet()
model.load_state_dict(torch.load(PATH))
correct = 0
total = 0
with torch.no_grad():
for data in loader():
images, labels = zip(*data)
images = np.array(images).astype('float32')
labels = np.array(labels).astype('int64')
images = torch.from_numpy(images).unsqueeze(1)
labels = torch.from_numpy(labels)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the {:d} test images: {:f}%'.format(total, 100 * correct / total))
return model
PATH = './mnist_pytorch.pth'
test_loader = dataReader('t10k.images', 't10k.labels', 64, True)test(PATH, test_loader)
单元测试3 - 机器学习初级 (2022-08-19)
1. 梯度下降
题目
梯度下降(gradient descent)在机器学习中应用十分的广泛, 不论是在回归问题还是分类问题中, 它的主要目的是通过迭代找到目标函数的最小值, 或者收敛到最小值. 以线性回归问题为例分析梯度下降的计算过程, 模型假定:
y = w * x + b,x, b为一维向量. x为输入向量, y_pred为前向输出, y为实际输出, w, b为模型参数, 损失函数定义为loss = (y - y_pred)$^2$, 训练的目标是使loss最小化, 设步长或学习率为1.0, 若采用梯度算法, 试问:
答案
当x = 3.0, y = 4.0, w = 2.0, b = 2.0,
前向计算的输出y_pred值是8,
梯度反向传播后, w更新后的值是-22,
b更新后的值是-6;
当x = 4.0, y = 4.0, w = 2.0, b = 2.0,
梯度反向传播后, w更新后的值是-46,
b更新后的值是-10
2. 手工推导对应变量相对于loss的梯度
题目
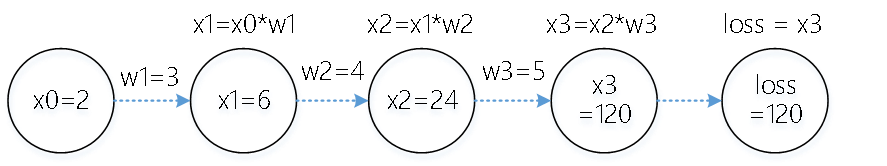 深度学习平台可以帮我们简化编程, 自动完成梯度的计算和参数的更新. 虽然全序列的线性变换没实际意义, 但可帮助我们理解梯度的反向传播机理. 手工方式推导对应变量相对于loss的梯度.
深度学习平台可以帮我们简化编程, 自动完成梯度的计算和参数的更新. 虽然全序列的线性变换没实际意义, 但可帮助我们理解梯度的反向传播机理. 手工方式推导对应变量相对于loss的梯度.
dloss/dloss = [填空1]
dloss/dx3 = [填空2]
dloss/dw3 = [填空3]
dloss/dx2 = [填空4]
dloss/dw2 = [填空5]
dloss/dx1 = [填空6]
dloss/dw1 = [填空7]
取学习率lr = 1.0, 利用梯度下降法来更新参数, 当梯度反向传播时, 更新后的参数值:
w3值为:[填空8]; w2值为:[填空9]; w1值为:[填空10]
答案
dloss/dloss = 1
dloss/dx3 = 1
dloss/dw3 = 24
dloss/dx2 = 5
dloss/dw2 = 30
dloss/dx1 = 20
dloss/dw1= 40
取学习率lr = 1.0, 利用梯度下降法来更新参数, 当梯度反向传播时, 更新后的参数值为:
w3值为: -19; w2值为: -26; w1值为: -37
3. 验证手工推导的结果是否一致
题目
利用pytorch框架计算梯度, 验证手工推导的结果是否一致.
import torch
from torch.autograd import Variable
x0 = torch.tensor([2.0])
wl = torch.tensor([3.0], requires_grad=True)
w2=torch.tensor([4.0], requires_grad=True)
# Variable存在于早期版本, 现在已经取消, 取代它的是在Tensor中通过设置requires_grad =True自动包含了梯度支持
w3 = Variable(torch.tensor([5.0]), requires_grad=True)
x1 = xO * w1
x2=x1 * w2
x3 = x2 * w3
loss=x3
x1.retain_grad(), x2.retain_grad(), x3.retain_grad()
loss.backward()
loss的梯度[填空1]
w3的梯度[填空2]
x3的梯度[填空3]
答案
loss的梯度loss.grad
w3的梯度w3.grad
x3的梯度x3.grad
4. 利用pytorch框架验证第一题中的计算结果
题目
利用pytorch框架验证第一题中的计算结果. 代码的目标是循环两次输入两种数据, 更新参数.
代码
import torch
def get_grad2():
lr = 1.0
for x, y in ((3.0, 4.0), (4.0, 4.0)):
w = torch.tensor([2.0], requires_grad=True)
b = torch.tensor([2.0], requires_grad=True)
x = torch.tensor([x])
y = torch.tensor([y])
y_pred = torch.mm(x, w) + b
loss = (y_pred - y) ** 2
loss.backward()
with torch.no_grad():
w = w - lr * w.grad
b -= lr * w.grad
w.grad.zero_() # w梯度归0
b.grad.zero_() # b梯度归0
get_grad2()
5. 试手工推导向量的偏导
题目
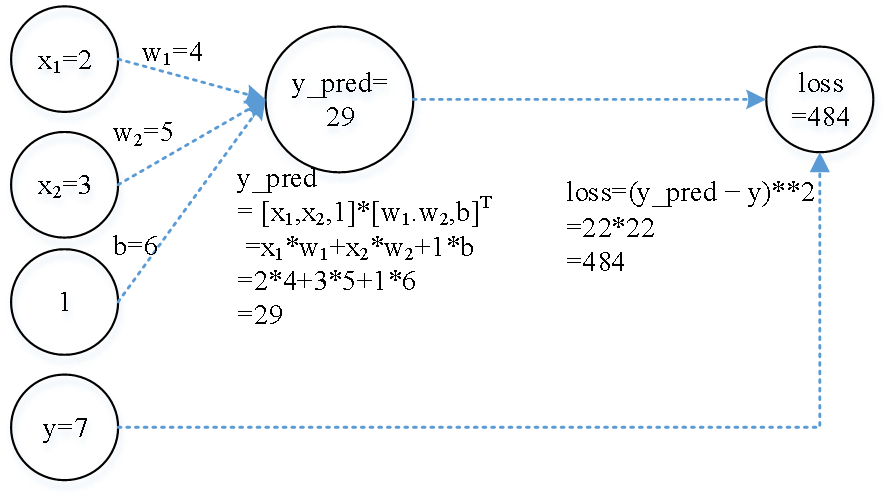
前面我们推导了单变量的梯度, 实际应用中输入数据和参数往往是向量. 试手工推导向量的偏导(实际变量是浮点数, 省略了小数点后的0)
$\frac{\mathrm{d}loss}{\mathrm{d}y_prep}$ = [填空1], $\frac{\partial loss}{\partial w_{1}}$ = [填空2]
$\frac{\partial loss}{\partial w_{2}}$ = [填空3], $\frac{\partial loss}{\partial b}$ = [填空4]
取学习率lr = 1.0, 利用梯度下降法来更新参数, 当梯度反向传播时, 更新后的参数值为:
W1值为: [填空5]; W2值为: [填空6]; b值为: [填空7]
答案
$\frac{\mathrm{d}loss}{\mathrm{d}y_prep} = 44$
$\frac{\partial loss}{\partial w_{1}} = 88$
$\frac{\partial loss}{\partial w_{2}} = 132$
$\frac{\partial loss}{\partial b} = 44$
取学习率lr = 1.0, 利用梯度下降法来更新参数, 当梯度反向传播时, 更新后的参数值为:
W1值为: -84; W2值为: -127; b值为: -38
6. 用pytorch实现如图所示的计算图
题目
代码
import torch
def get_grad4(lr = 1.0):
x =torch.tensor([[2.0, 3.0]])
y =torch.tensor([7.0])
w =torch.tensor([[4.0], [5.0], requires_grad=True)
b = torch.tensor([6.0], requires_grad=True)
y_pred = torch.mm(x, w) + b
loss=(y_pred - y) ** 2
loss.backward()
with torch.no_grad():
for param in [w ,b]:
param -= lr*param.grad
param.grad.zero_()
7. 用pytorch实现线性回归
题目
用pytorch实现线性回归, 假设模型为y =X * W + b,X为4维行向量, w为4维列向量. readMatrix函数用于从文件中恢复矩阵或向量.
data_iter函数用于构建生成器. 操作函数采用均方差.
代码
import torch, random
def data_iter(x_file, y_file, batch_s):
x = readMatrix(x_file) # x.shape (1000,4)
y = readMatrix(y_file) # y.shape ( 1000,)
features = torch.tensor(x)
labels = torch.tensor(y)
num_examples = len(features)
indices = list(range(num_examples))
#这些样本是随机读取的,没有特定的顺序random.shuffle(indices)
for i in range(0, num_examples, batch_s):
batch_indices = torch.tensor(indices[i: min(i + batch_s, num_examples)])
yield features[batch_indices], labels[batch_indices]
7.1 用pytorch基础计算实现线性回归问题的求解
题目
用pytorch基础计算实现线性回归问题的求解
代码
import torch
def train_regress(x_file, y_file, n_epochs, batch_s, lr):
w = torch.normal(0, 0.01, size=(4, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
for epoch in range(n_epochs):
for x, y in data_iter(x_file, y_file, batch_s):
y_pred = torch.matmul(x, w) + b
loss = (y_pred - y.unsqueeze(1)) ** 2 / 2
loss.sum().backward()
# 使用参数的梯度更新参数
with torch.no_grad():
for param in [w, b]:
param.data = param.data - lr * param.grad / batch_sparam.grad.zero_()
print('predict: w=0,b={}'.format(
w.detach().numpy(), b.detach().numpy()[0]))
train_regress()
7.2 用pytorch主级接口实现线性回归问题的求解
题目
用pytorch主级接口实现线性回归问题的求解
代码
import random
import struct
import numpy as np
import torch.nn as nn
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(4, 1) # 输入和输出的维度
def forward(self, x):
y_pred = self.linear(x)
return y_pred
def trainer(x_file, y_file, model_path, num_epochs, batch_size, lr):
model = LinearRegression()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
for epoch in range(num_epochs):
for x, y in data_iter(x_file, y_file, batch_size):
y = y.unsqueeze(dim=1)
# 向前传播
y_pred = model(x)
loss = criterion(y_pred, y)
# 向后传播
optimizer.zero_grad() # 注意每次迭代都需要清零
loss.backward()
optimizer.step()
print('epoch:{} loss: {:.6f}'.format(epoch, loss.item()))
for name, param in model.named_parameters():
print(name, param)
单元测试2 - Python中级 (2022-08-12)
1. 矩阵运算
题目
numpy是Python中常用的矩阵运算库,numpy.ndarray表达的矩阵也常用于图像矩阵的表示。熟练矩阵运算是基本技能。
代码
import numpy as np
a = np.array(range(1, 5)).reshape((2, 2)) # 创建矩阵[[1 2][3 4]]
b = np.arange(5, 9).reshape((2, 2)) # 创建矩阵[[5 6][7 8]]
# a,b矩阵运算结果为[[19 22][43 50]],用矩阵乘
c = np.dot(a, b)
# a,b矩阵运算结果为[[23 34][31 46]],用矩阵乘
d = np.dot(b, a)
# a,b矩阵运算结果为[[5 12][21 32]],用矩阵元素乘
e = np.multiply(a, b)
2. 使用矩阵表示图像
题目 用于图像矩阵的表示。熟练矩阵运算是基本技能。
代码
import numpy as np
a = np.array([[1, 2], [3, 4]])
# 扩展矩阵a的维度,由(2,2)->(2,1,2)
b = np.expand_dims(a, axis=1)
# 删除维度为1的维度,b矩阵(2,1,2)->(2,2)
c = np.squeeze(b, axis=1)
print(a * 2) # 输出结果为[填空3]
print(np.array([1, 2] * 2)) # 输出结果为[填空4]
print(np.amax(a, axis=1)) # 输出结果为[填空5]
3. 从idx中读取数据,并恢复为对应的矩阵
题目
3.根据idx文件格式,从idx中读取数据,并恢复为对应的矩阵,即返回numpy.ndarray对象,利用字典将编码转为对应的类型符。
代码
import struct, numpy as np
code2type = {0x08: 'B', 0x09: 'b', 0x0B: 'h', 0x0c: 'i', 0x0D:'f', 0x0E:'d'}
def readMatrix(filename):
with open(filename, 'rb') as f:
buff = f.read()
offset = 0
# 格式定义,>表示高位在前,I表示4字节整数
fmt = '>HBB'
_,dcode, dimslen = struct.unpack_from(fmt, buff, offset)
offset += struct.calcsize(fmt)
fmt = '>{}I'.format(dimslen)
shapes = struct.unpack_from(fmt, buff, offset)
offset += struct.calcsize(fmt)
fmt = '>' + str(np.prod(shapes)) + code2type[dcode]
matrix = struct.unpack_from(fmt, buff, offset)
matrix = np.reshape(matrix, shapes).astype(code2type[dcode])
return matrix
4. 从idx格式的mnist图片和标签文件中创建生成器用于模型的批量训练
题目
从idx格式的mnist图片和标签文件中,创建生成器,用于模型的批量训练。要求返回的批量数据列表格式形如:
[(img1,label1), (img2,label2), ...]列表中的元素为图片和标签对,列表中的元素顺序是随机的
代码
import random
def dataReader(img_file, label_file, batch_size=24, drop_last=False):
mnist_matrix = readMatrix(img_file) # (60000,28,28)
mnist_label = readMatrix(label_file) #(60000,)
buff = list(zip(mnist_matrix, mnist_label))
def batch_reader():
random.shuffle(buff)
b = []
for sample in buff:
b.append(sample)
if len(b) == batch_size:
yield b
b = []
if not drop_last and len(b) != 0:
yield b
return batch_reader
5. 利用numpy.random的均匀分布生成向量
题目
利用numpy.random的均匀分布生成3000个元素值为[0,1000)的4维向量,参考sturct模块中的pack, pack_into, unpack, unpack_from函数
代码
import struct, numpy as np
type2code = {'uint8': 0x08, 'int8': 0x09, 'int16': 0x0B, 'int32': 0x0C, 'float32': 0x0D, 'float64': 0x0E}
def createMatrix(low=0, high=1000, size=[4, 3000]):
return np.random.uniform(low, high, size).astype('>f4')
def writeMatrix2(filename, matrix=createMatrix()):
print(matrix.shape)
with open(filename, 'wb') as f:
shapes = matrix.shape
fmt = '>HBB'
fhead = struct.pack(fmt, 0, type2code[matrix.dtype.name], len(shapes))
f.write(fhead)
fmt = '>{}I'.format(len(shapes))
fhead = struct.pack(fmt, *shapes)
f.write(fhead)
f.write(matrix)
writeMatrix2('D:/temp.idx')
6. 添加白噪声
题目
假定线性表达式为y=c1*x1+c2*x2+cg*xg+c4*x4+c5,根据向量列表生成的向量计算表达式的值y,在y值中加入白噪声,作为标签值
代码
import numpy as np
def createLabel(matrix, coef=[1, 2, 3, 4, 5], dtype='>f4'):
w = np.array(coef[:4])
y = np.dot(matrix, w) + coef[4]
noise = np.random.standard_normal(matrix.shape[1]) * 100
y += noise
return y.astype(dtype)
7. 将训练集打包成tar文件
题目
深度学习中用于训练的图片文件一般用单独的文件来保存,为避免目录下文件太多,通常会将文件目录打包成单一的tar文件,训练时直接从tar中解析出图片,而不用解压到目录下再操作。下列代码将mnist中的图片矩阵转成png图片后打包到单一的文件当中。
代码
import PIL.Image as Image, time, tarfile
from io import BytesIO
matrix = readMatrix('train-images-idx3-ubyte')
def createImgTar(filename='train.images.tar', matrix=matrix):
with tarfile.open(filename, 'w') as tar:
for i in range(len(matrix)):
bio = BytesIO()
im = Image.fromarray(matrix[i])
im.save(bio, format='PNG')
# 构建Tarinfo对象,添加文件名、缓冲区长度、文件创建时间
info = tarfile.TarInfo(name="images/{:05d}.png".format(i))
info.size = bio.getbuffer().nbytes
info.mtime = time.time()
bio.seek(0)
# 添加的IO文件必须是二进制形式
tar.addfile(info, bio)
8. 从tar中读取.txt文件并统计单词频率
题目
顺序从tar文件中读取.txt的文本文件,去除换行、标注符号后,统计单词频率,保留频率大于5的单词。
代码
import json, collections, tarfile, re, string
def tokenize(srcfile='txt.tar', suffix='txt'):
pattern = re.compile('.*\.' + suffix + '$')
with tarfile.open(srcfile, mode='r') as tarf:
tf = tarf.next()
while tf != None:
if bool(pattern.match(tf.name)):
yield tarf.extractfile(tf).read().decode('utf-8').rstrip('In\r').translate(
str.maketrans(",", string.punctuation)).lower().split()
tf = tarf.next()
def buildDict(dstfile='word_dict.json', srcfile='txt.tar', suffix='txt', cutoff=5):
word_freq = collections.defaultdict(int)
for doc in tokenize(srcfile, suffix):
for word in word_freq:
word_freq[word] += 1
word_freq = [x for x in word_freq.items() if x[1] > cutoff]
dictionary = sorted(word_freq, key=lambda x: (-x[1], x[0]))
words, _ = list(zip(*dictionary)) # 用*,将元组解压为列表
word_idx = dict(list(zip(doc, range(len(words)))))
word_idx['<unk>'] = len(words)
with open(dstfile, 'wb') as f:
f.write(json.dumps(word_idx, ensure_ascii=False, indent=4).encode('utf8'))
return word_idx
9. 不同图像类型的转换和通道变换
题目 丰富多样的图片是提升机器视觉领域深度模型泛化能力的重要手段,通过对训练数据进行增强处理可以丰富训练数据,即通过添加噪声、轻微旋转、缩放等操作,在不改变图像语义的情况下对图像进行轻微变形可大幅提升图片的多样性。掌握图像的基本操作是必备技能。不同工具对图片的存储类型不一样,通道顺序也会不同,下列代码是掌握不同图像类型的转换和通道变换。
代码
import numpy as np
from PIL import Image
import cv2
# 读取彩色图片
img = Image.open('./temp.jpeg').convert('RGB')
# Image转为ndarry
img = np.array(img)
# RGB图像转为BGR
img = img[:, :, (2, 1, 0)]
cv2.imshow('img', img)
# BGR图像转为RGB
img = img[:, :, (2, 1, 0)]
# ndaary转为Image
img = Image.fromarray(img)
img.show()
cv2.waitKey(0)
10. 利用PIL模块中的图像增强工具对图像进行变形
题目
利用PIL模块中的图像增强工具对图像进行变形
代码
from PIL import Image, ImageEnhance
import numpy as np
img = Image.open('./lena.jpg').convert('RGB')
img.show()
delta = np.random.uniform(0.5, 1.5)
# 大小变化
shape = (np.array(img.size) * delta).astype('i')
img1 = img.resize(shape)
img1.show()
# 亮度变化
img2 = ImageEnhance.Brightness(img).enhance(delta)
img2.show()
# 对比度变化
img3 = ImageEnhance.Contrast(img).enhance(delta)
img3.show()
# 锐度变化
img4 = ImageEnhance.Sharpness(img).enhance(delta)
img4.show()
# 色度变化
img5 = ImageEnhance.Color(img).enhance(delta)
img5.show()
单元测试1 - Python初级 (2022-08-05)
1. 输出5个奇数
题目
下列代码的功能是:通过循环打印出共5个奇数,输出格式如下:
1 3 5 7 9
请补充代码
[填空1] i [填空2] range ([填空3] ,10 ,[填空4]):
print(i,[填空5])
A.0 B.1 C.2 D.3 E.9 F.9.5 G.10
H.END=' ' I.end=' ' J.SEP=' ' K.sep=' '
L.if M.for N. while
O.in Q.at R.is
代码
for i in range(1, 10, 2):
print(i, end=' ')
正确答案
M;O;B;C;I
2. 切片
题目
列表是基础结构,执行下列代码
a=[]
for i in range(4) :
a.append(i)
print(a[2:3], a[2:], a[2::2], a[2::-1], a[2:3:-1])
补充下列代码的输出结果。
[填空1] [填空2] [填空3] [填空4] [填空5]
A.0 B.1 C.2 D.[] E.[2] F.[2,3]
G.[2,3,4,] H.[0,1,2] I.[0,1,2,3]
J.[2,1,0] K.[3,2,1,0]
正确答案
E;F;E;J;D
3. 基本运算
题目 基本运算,代码如下,请补充输出结果
a=9
b=2
print(a/b, a//b, a*b, a**b,a%b)
[填空1] [填空2] [填空3] [填空4] [填空5]
A.0 B.1 C.2 D.4
E.4.5 F.5 G.18
H.81 I.512
正确答案
E;D;G;H;B
4. IP地址转换
题目
网络中主机地址ipv4,是32位无符号整数,如: cOa81f01H,通常用字符串表示,如: “192.168.31.1”,转换规则是每个字节为10进制数,高位在前,低位字节在后。下面的代码将串表示的地址转为对应的无符号整数
11000000 10101000 00011111 00000001
0:192 1:168 2:31 3:1
3232243457,c0a81f01
def ipstr2int(ipstr) :
iplist = ipstr.split([填空1])
for i in iplist:
print("{[填空2]}".format(int(i)), end=' ')
print()
ip=0
for idx, i in enumerate(iplist) :
print("{}:{}".format([填空3], [填空4]), end=' ')
ip [填空5]
ip += int(i)
print("\n{:d},{:x}".format(ip, ip))
ipstr2int('192.168.31.1')
A.'\n' B.' ' C.'\t' D.'.'
E.8b F.8d G.:0>8d H.:0>8b
I.i J.idx K.int(i)
L.<<8 M.>>8 N.<<=8 O.>>=8
P.>>8*idx R.<<8*idx
代码
def ipstr2int(ipstr):
iplist = ipstr.split('.')
for i in iplist:
print("{:0>8b}".format(int(i)), end=' ')
print()
ip = 0
for idx, i in enumerate(iplist):
print("{}:{}".format(idx, i), end=' ')
ip <<= 8
ip += int(i)
print("\n{:d},{:x}".format(ip, ip))
ipstr2int('192.168.31.1')
正确答案
D;H;J;I;N
5. 字母频率排序
题目
深度学习中处理文本时,经常需要从文件中生成字典,方法是先统计各单词出现的频率,去掉频率较低的单词。下列代码先删除字符串两边的空格,再按空格进行单词分割,并统计单词的频率,只保留频率大于1的单词,最后按频率降序,同频率的则按单词顺序升序排列。
预期输出结果以下:
[('a',4),('b',3),('c',3)]
请补充代码:
import collections,re
def CreateDict(string):
string=re.split("\s+", string.strip() )
word_dict = collections.defaultdict(int)
for i in string:
word_dict[填空1] += 1
word_dict = [x for x in [填空2] if [填空3] > 1]
word_dict = sorted(dict, key= lambda x:([填空4],[填空5]))
return word_dict
print(CreateDict(" c b a d c a b c a b a "))
A.(i) B.[i] C.{i}
D.x E.x(O) F.-x(O) G.x[0] H.-x[0]
I.x(1) J.-x(1) K.x[1] L.-x[1]
M.word_dict N.word_dict.items() O.word_dict[x]
代码
import collections, re
def CreateDict(string):
string = re.split("\s+", string.strip())
word_dict = collections.defaultdict(int)
for i in string:
word_dict[i] += 1
word_dict = [x for x in word_dict.items() if x[1] > 1]
word_dict = sorted(dict, key=lambda x: (-x[1], x[0]))
return word_dict
print(CreateDict(" c b a d c a b c a b a "))
正确答案
B;N;K;L;G
6. 构建生成器返回字母
题目
深度学习的训练采用迭代训练方式,每次向模型输出一组数据去更新模型参数。因此需要我们构建生成器,每次访问自动返回一组数据。下列函数用于返回一个生成器,循环时,每次返回一个字符。输出结果如下:
a b c d e
补充代码:
def fun[填空1]:
i = 0
[填空2] i<len:
[填空3] chr(i+ord('a'))
i += 1
[填空4] x in [填空5]:
print(x, end=' ')
A.[len] B.(len) C. {len}
D.if E.while F.for
G.fun H.fun[5] I.fun(5)
J.pass K.return L.yield
M.break N.continue
代码
def fun(len):
i = 0
while i < len:
yield chr(i + ord('a'))
i += 1
for x in fun(5):
print(x, end=' ')
正确答案
B;E;L;F;I
7. 利用生成器批量输出数据
题目
利用生成器,我们可以对原始数据的顺序打乱后,批次输出2个数据,用于训练,不足批次的元素也输出。输出形式如下,注意每次输出的顺序会不同。
0: [6,8]
1: [4,0]
2: [3,2]
3: [5,7]
4:[1]
补充代码:
import random
def reader(buff):
random.shuffle(buff)
def batch_reader(batch_size, drop_last=True):
b = []
for instance in buff:
b.append (instance)
if len(b)== batch_size:
[填空1]
[填空2]
if drop_last is False and len(b)!= 0:
[填空3]
return[填空4]
data=[]
for i in range(9):
data.append (i)
for idx,i in[填空5](reader(data)(2,False)):
print("{}: {}".format (idx,i))
A.return b B.return buff C.yield b D.yield buff E.b=[]
F.b=() G.reader H.batch_reader I.reader(buff)
J.batch_reader(batch_size, drop_last) K.range L.enumerate
代码
import random
def reader(buff):
random.shuffle(buff)
def batch_reader(batch_size, drop_last=True):
b = []
for instance in buff:
b.append(instance)
if len(b) == batch_size:
yield b
b = []
if drop_last is False and len(b) != 0:
yield b
return batch_reader
data = []
for i in range(9):
data.append(i)
for idx, i in enumerate(reader(data)(2, False)):
print("{}: {}".format(idx, i))
正确答案
C;E;C;H;L
8. 读取目录下的png文件
题目
深度学习训练所用的图片通常是单个文件,需要我们从目录下读取图片文件列表。下列代码从目录中生成只包含png图片文件的列表。
注意扩展名可能既有大写也有小写的,目录下可能还有子目录或基他类型的文件。d:/testdir目录结构如下
dir1,1.png,1.txt,2.PNG,3.pnG
期望输出以下结果:
['D:/testdir/1.PNG','D:/testdir/2.png', 'D:/testdir/3.pnG']
补充代码,请参考python的内置函数的使用。
import os
def subdir_list(dirname):
filelist= [填空1] ([填空2] x: dirname+x, os.listdir(dirname))
def ispng(x):
return x.split('.')[-1].lower ()=="png"
return [填空3]( [填空4] (ispng,[填空5] (os.path.isfile,filelist)))
print(subdir_list('D:/testdir/'))
A.list B.tuple C.map D.filter I.lambda J.str K.iter L.zip
M.type
代码
import os
def subdir_list(dirname):
filelist = map(lambda x: dirname + x, os.listdir(dirname))
def ispng(x):
return x.split('.')[-1].lower == "png"
return list(filter(ispng, filter(os.path.isfile, filelist)))
print(subdir_list('D:/testdir/'))
正确答案
C;I;A;D;D
9. 利用list存储矩阵
题目
深度学习中应用最多的计算是矩阵运算,list也可用于存储矩阵数据,欲输出以下结构的列表:
[[[11, 12, 13], [14, 15, 16]], [[21, 22, 23], [24, 25, 26]]
请补充代码:
def createMatrixList(len, rows,cols):
matrix_list=[]
for i in range (len):
matrix=[]
for j in range([填空1]):
elem = []
for k in range([填空2]):
[填空3].append ((i + 1) * 10 +(j*cols)+ (k +1))
[填空4].append(elem)
matrix_list.append(matrix)
return matrix_list
print(createMatrixList(2,2,3))
A.len B.rows C.cols D.elem E.matrix F.matrix_list
matrix[1][1][1]的值是[填空5]
A.11 B.12 C.14 D.15 E.21 F.22 G.24 H.25
代码
def createMatrixList(len, rows,cols):
matrix_list=[]
for i in range (len):
matrix=[]
for j in range(rows):
elem = []
for k in range(cols):
elem.append ((i + 1) * 10 +(j*cols)+ (k +1))
matrix.append(elem)
matrix_list.append(matrix)
return matrix_list
print(createMatrixList(2,2,3))
正确答案
B;C;D;F;H
10. 利用numpy存储矩阵
题目
深度学习中应用最多的计算是矩阵运算,用list结构存储矩阵操作不方便,而且运算效率很低。因此矩阵操作通常使用numpy模块,下列代码用于生成以下形式的矩阵,元素值为8位无符号整数,常用于表示图像的像素值。下列代码欲生成下列矩阵:
[[[11 12 13 14]
[15 16 17 18]]
[[21 22 23 24]
[25 26 27 28]]
[[31 32 33 34]
[35 36 37 38]]]
请补充代码:请参考numpy模块的使用
import numpy as np
def createMatrix(len,rows,cols):
matrix = np.zeros ([len, rows,cols]).[填空1]('ubyte')
for i in range([填空2]):
for j in range([填空3]):
for k in range([填空4]):
matrix[i,j,k] =((i + 1) * 10 + j * cols + k + 1)
return matrix
matrix=createMatrix(3,2,4)
print (matrix)
A.dtype B.astype C.len D.rows E.cols
print (matrix[1][1][1])输出结果为:[填空5]
A.11 B.12 C.15 D.16
E.21 F.22 G.25 H.26
I.31 J.32 K.34 L.35
代码
import numpy as np
def createMatrix(len, rows, cols):
matrix = np.zeros([len, rows, cols]).astype('ubyte')
for i in range(len):
for j in range(rows):
for k in range(cols):
matrix[i, j, k] = ((i + 1) * 10 + j * cols + k + 1)
return matrix
matrix = createMatrix(3, 2, 4)
print(matrix)
正确答案
B;C;D;E;H